《数据视图化表达:问卷搭建引擎设计原理》
作者:skique
时间:2024-03-18
发布于:前端早读课
前言
主要讨论了问卷业务抽象和数据视图化表达在问卷搭建引擎设计中的重要性。通过分析问卷领域特性和设计原理,提出了问题消解复杂性、题型物料化和渲染统一等设计框架,以实现高效、灵活的问卷平台。最终目的是为问卷设计、数据收集和分析提供有益的启示和指导,提高问卷调查的效率和准确性。今日前端早读课文章由 @陶双分享,由 @freedom 投稿。
正文从这开始~~
开源项目 XIAOJU-SURVEY 关于问卷搭建设计的原理分享:https://github.com/didi/xiaoju-survey
背景
我们深知问卷调查在各个领域中的重要性以及传统问卷调查方法的局限性。因此,有必要开发一种高效、灵活的问卷平台,以满足不同用户的需求,并提高问卷调查的效率和准确性。
为了更好地满足调研需求,提高数据收集、分析和表达的效率,本文将从业务抽象、数据视图化表达等方面出发,分析问卷领域的特性,探讨设计一套满足问卷领域搭建方案的架构。我们希望通过本文的讨论,为问卷平台的设计与开发提供一些有益的启示和指导。
问卷业务抽象
这还要从问卷业务抽象开始说起,设计问卷的目的是为了回收数据,而回收数据则是为了提供数据支持进行分析。
问卷通常需要经历几个阶段,包括设计、发布、投放、回收和分析。为了更好地理解和处理问卷调查的相关业务,我们可以将问卷领域拆分为三个子领域,分别是问卷设计域、问卷回收域和问卷分析域。
问卷设计域负责创建问卷并发布问卷,回收域负责收集数据,分析域负责对收集到的数据进行统计分析和洞察。在整个过程中,数据的流动是核心,从设计到回收再到分析,数据始终贯穿其中,为用户提供重要的信息和决策依据。
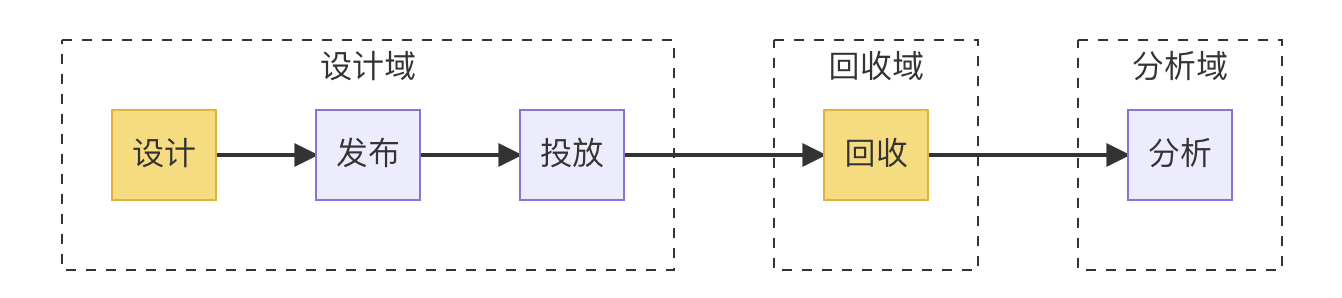
业务视角到技术视角的映射,将主体聚焦到数据,设计域关注的是问卷的数据的 schema 设计,回收领域关注的是数据的采集,分析领域关注的是数据的分析:

抽象为三个方面:
数据的表达(模型设计)问卷的模型设计。这涉及到定义问题、选项、逻辑关系等信息的结构和格式,以确保问卷的完整性和准确性。通过设计合适的数据模型,我们能够清晰地描述问卷的结构和逻辑,为后续的数据采集和分析提供基础。
数据的流动(服务插拔)通过设计灵活的服务插拔机制,可以自定义引入敏感词过滤,问卷发布审批等安全插件,保证数据流动的安全合规性
数据的交互(界面设计),解决数据到界面的最后一公里,界面设计是一个产品的载体,因为产品最终是面向用户角色,如何让用户体验更好、用户体验贯穿业务核心流程,提高创编收发过程的整体效率
综上所述,在问卷领域的整体业务抽象模型中,数据的交互是一个非常重要的方面,以下的讨论将聚焦在数据的交互上,即数据的视图化表达。
数据的交互
在数据流动图的基础上考虑以下两点:
谁操作数据的交互
通过何种方式操作数据的交互
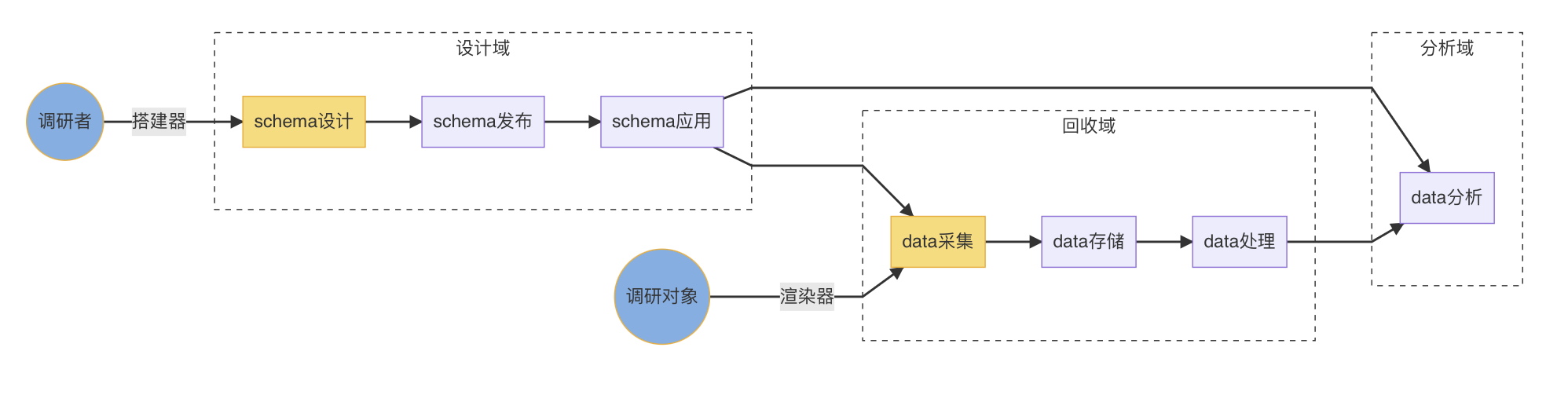
数据的交互主要发生在设计域和回收域,面向调研者和调研对象分别引入搭建器和渲染器用于数据的交互。
对问卷进一步抽象,题型的目的是为了高效率的收集数据,也就是题型是数据的模具,题型和数据的关系,好比杯子和水,杯子设计出来是为了盛水。
所以问卷设计领域的搭建器是数据容器的工厂,题型是数据模具的表现形式,题型配置的是数据容器的约束方式,而问卷回收领域的渲染端的数据交互的核心是面向调研用户的的答题过程,才是真正盛满水的过程。
问卷领域特性
问卷结构解构
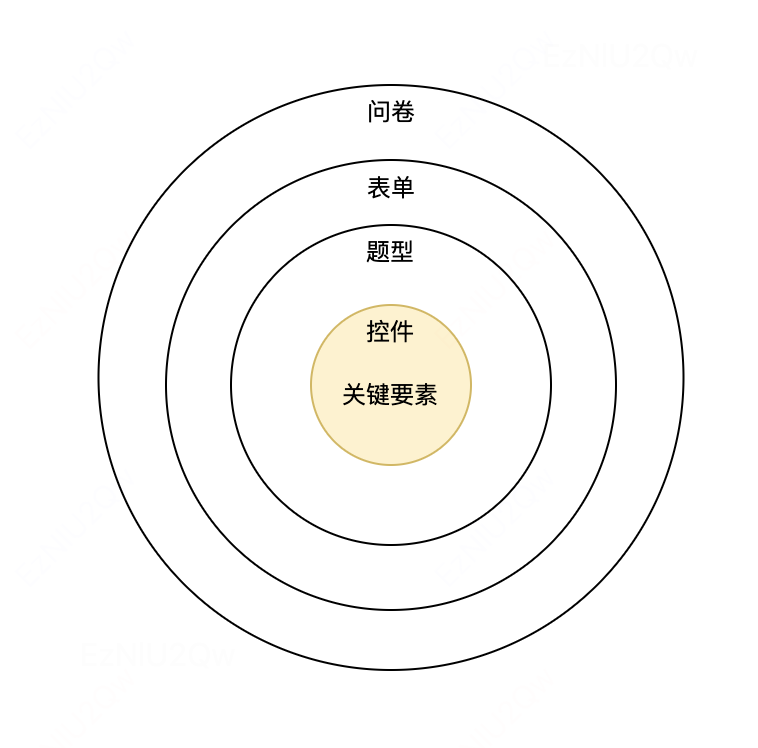
问卷的组成:是由控件到题型到表单到问卷,一层一层扩展而来,其中控件是区分题型的关键要素,也就是说什么类型的控件对应什么类型的题型,是一一对应的关系。
题型 = 标题 + 控件
表单 = n 个题型,n >= 1
问卷 = 欢迎语 + n 个表单 + 提交按钮,不考虑分页的情况,n = 1
问卷配置解构
按照作用方式分为两类:
定义界面显示,如显示序号、显示类型、显示分割线等、评分样式、引导提示文案
约束交互行为,如必填、输入限制、最多 / 最少选择、如必填、校验格式等等
按照作用范围分为五类:
作用在控件上,如输入限制,最多选择引导提示文案
作用在题型上,如显示序号、显示类型、显示分割线等
作用在表单上,如必填,最少选择、内容格式校验
作用在问卷上,如答题时长、答题次数等等
还有一类作用在数据适配上
静态的数据适配,在渲染器前进行的数据适配,如选项随机,选项分组等等
动态的数据适配:需要在答题过程中,根据用户选择的答案动态响应的配置,如标题 / 选项引用、跳转逻辑、显示逻辑等
问题是什么?
题目是问卷最核心和基础的组成部分,而复杂繁多的调研目的要求问卷内容高度灵活,这对题型的多样性和可用性提出了极高的要求。
分析实际使用,问卷搭建端和问卷渲染端既存在共通性也存在差异性,这在题型上呈现了类似于复杂笛卡尔积的结构。
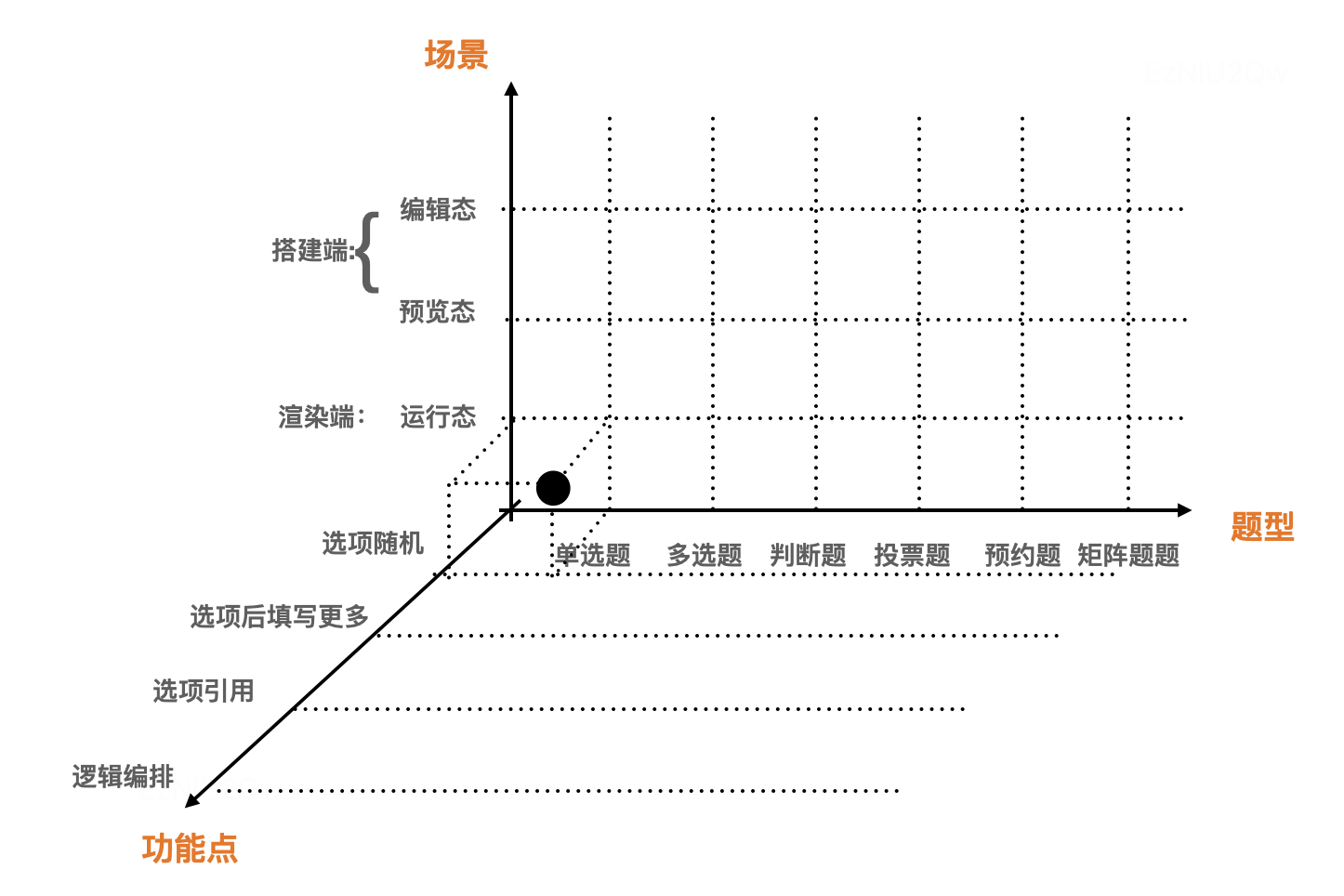
如何在数据视图化设计中管理三维笛卡尔积的复杂性呢?
也许系统的混乱并非业务本身之复杂,而是我们并不擅长处理『简单』,如何 “化繁为简”?
将目标系统按某个原则进行切分,切分的原则,是要便于不同的角色进行并行工作。通过合理的分解和抽象,使那些系统不再那么难懂。
如何消解复杂性
题型物料化
为了保障预览实时性和渲染一致性,提升题型的多状态管理能力,并降低题型设计的复杂性和成本、提升题型扩展的灵活性,采用题型物料化的设计思路。
抽离题型控件沉淀物料层,物料分层化设计:
分类型抽离通用逻辑沉淀为基础物料,以降低具体业务逻辑对这些基础物料的依赖。
不同题型物料基于相应类型的基础物料进行扩展,实现特定业务逻辑以做到题型隔离。
渲染统一
题型物料沉淀后由统一的题型组件提供搭建端和渲染端的题型渲染,那么如何满足不同场景下的题型侧重点呢?比如搭建端关注题型编排能力,渲染端关注题型填写选中和校验方面。
搭建端通过组件切面设计:通过插槽机制,搭建端可自定义题型包裹组件以实现题型编排的辅助功能,避免侵入式对题型组件做出修改。
渲染端通过构建渲染环境提供 form 组件包裹题型组件,在组件内管理了所有的表单项,即 fields 管理。实现了 addField 和 removeField 的方法,用于增加 / 删除表单项校验,通过 provide 将整个组件实例提供给题型组件,使得题型组件的有表单规则校验的能力。
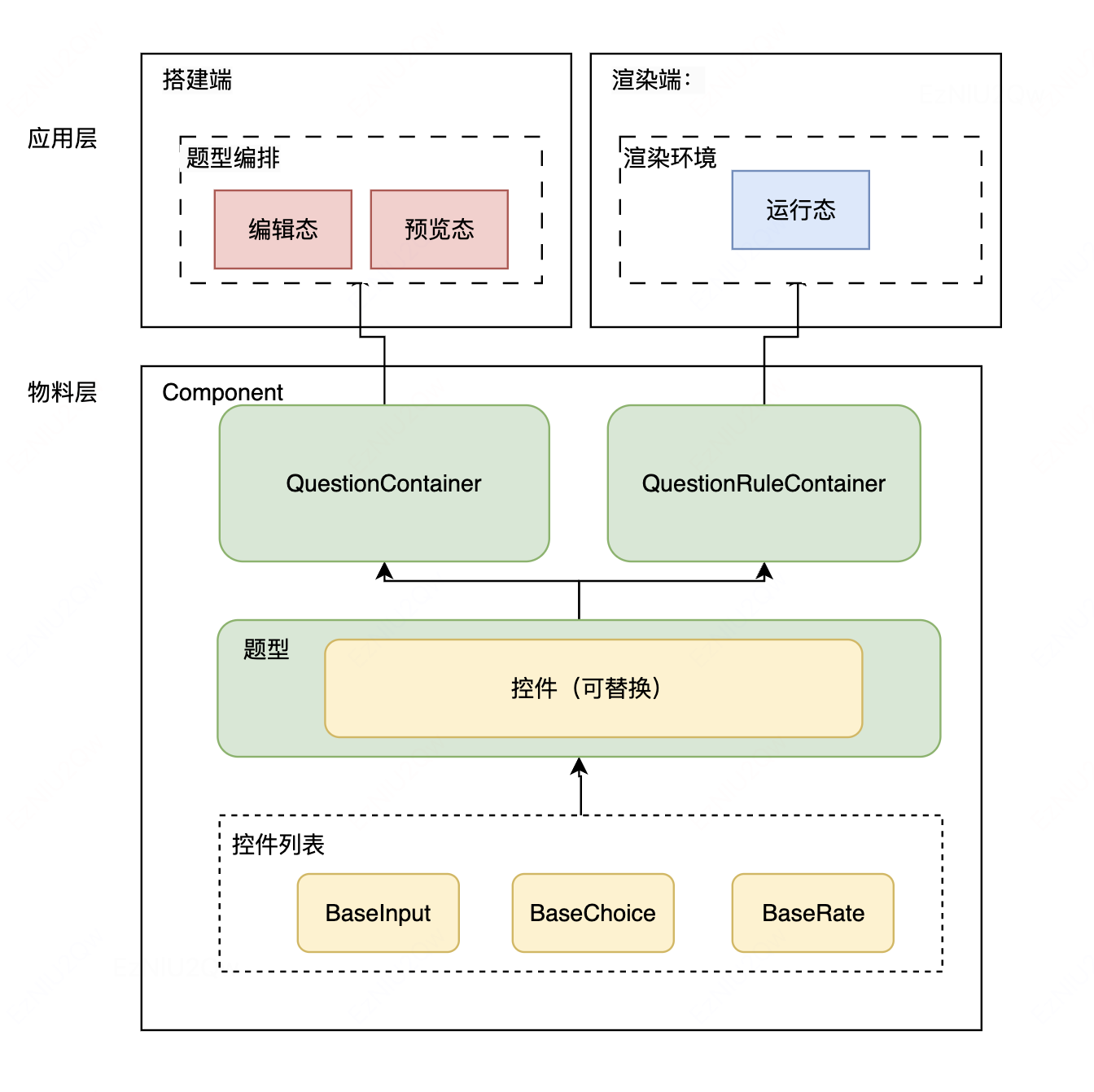
通过这种方式将题型的场景维度消解。
配置管理
在上述的物料化方案满足渲染统一后,怎么做配置管理呢?
搭建端引入设置器满足题型编排配置修改的能力。
渲染端引入题型 hooks 满足题型配置生效的能力,将各个题型配置解耦,抽象为相对集中的代码片段,Hooks 可以让我们组织更加内聚的逻辑单元。
设计框架
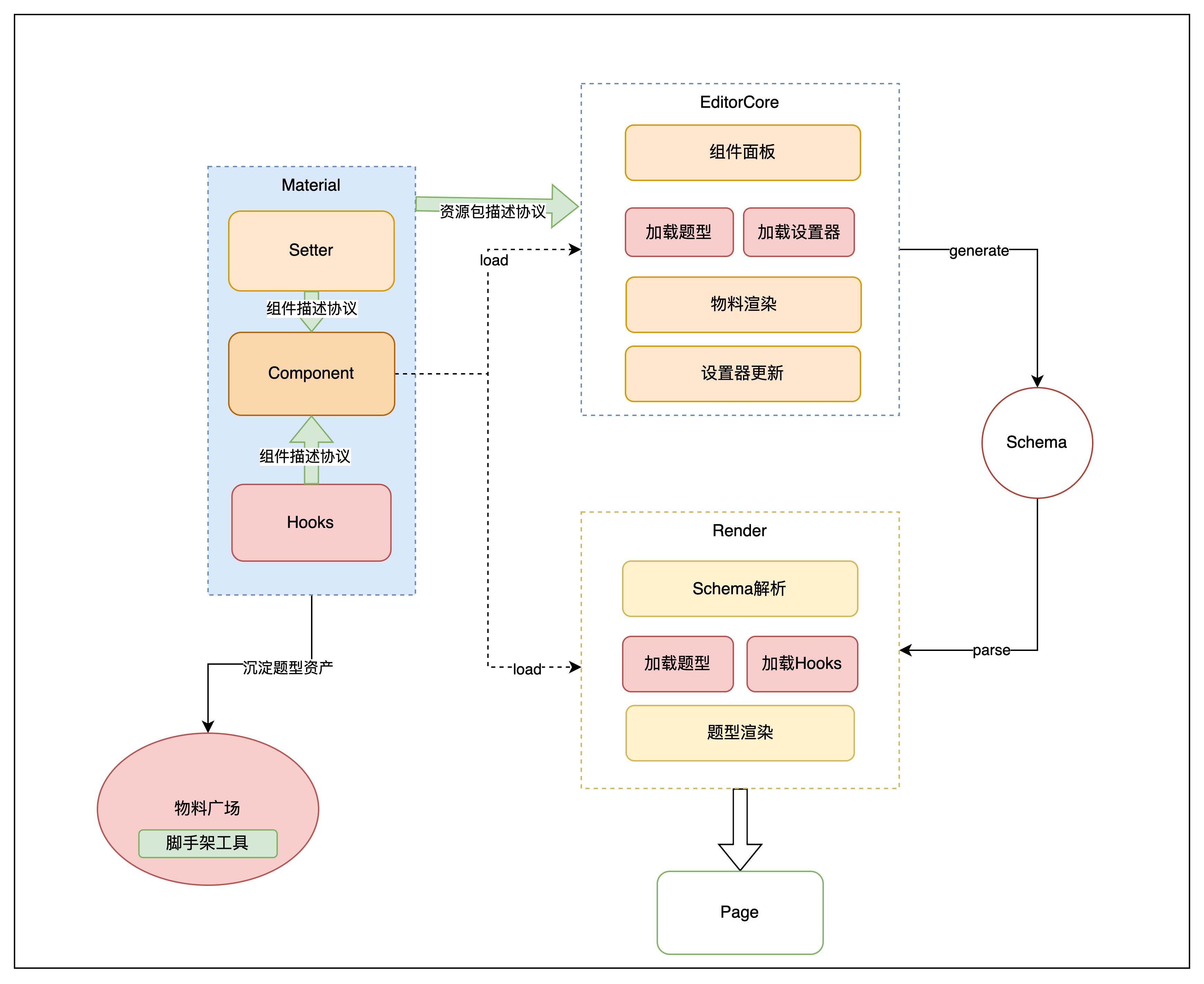
问卷物料设计
如图所示,问卷维护的物料类型可以分为三类:
Component,题型组件 = 标题 + 题型控件,响应分发到题的配置变化,完成数据采集能力。
Setter,设置器,提供对题型组件的配置进行更改的能力。
Hooks,题型 hooks,对应渲染端响应题型配置的代码片段 or 函数功能,举个例子,搭建端开启选项分组这一配置,渲染器需要响应这一配置,在渲染页面时运行对应的选项分组函数。
这三类物料之间是什么关系,通过什么关联起来?
题型描述协议,即定义题型描述的数据结构,采用配置化方案约束该题型 schema 结构,单个 schema 字段关联的设置器以及题型 hooks 函数。
搭建器设计
通过上面的问卷物料设计,我们维护一系列题型的物料集合,这些物料如何流入到搭建器?通过配置资源描述协议,这份协议规定了该搭建器加载哪些题型,可供组件面板选择。可用于题型画布搭建渲染。每个物料关联了设置器,加载并渲染设置器,设置器提供对题型配置修改和更新的能力。
渲染器设计
渲染器的核心是题型渲染和题型配置响应,问卷平台的题型可配置功能既然是对多个题型整体生效,是否我们可以引入渲染环境这个概念,渲染端题型功能交互依赖于渲染环境,渲染环境解析 schema,提供对题型整体关系的管理,实现如下功能:
统一的数据适配器,实现如题目序号、选项随机、默认选中第一项等功能
动态的视图数据处理,如标题引用、选项引用、显示逻辑、跳转逻辑等功能。基于交互变化动态加工数据
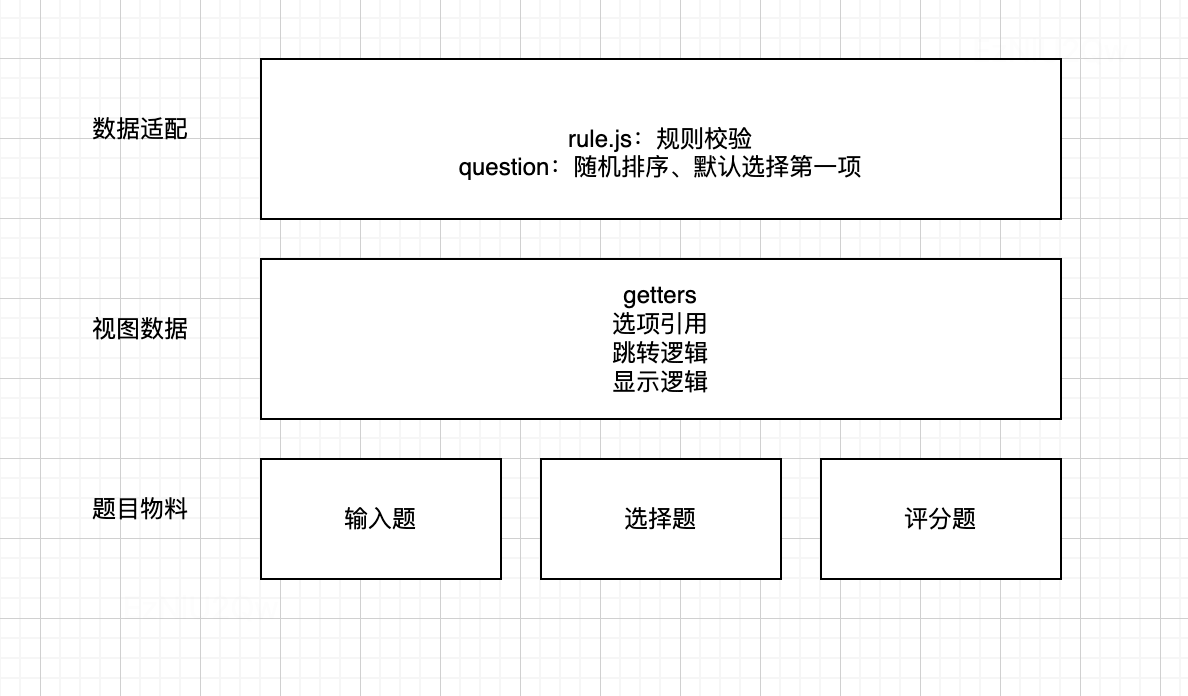
渲染器提供渲染环境,解析 schema, 将 schema 配置分发到渲染环境 (实现) or 分发到题,加载对应的题型和对应的题型 hooks,渲染答题页面。
写在最后
关于题型组件、设置器组件、题型 hooks 和题型描述协议以及资源描述协议的详细设计,后期会陆续推出相关文章更具体的论述,本文只做统领性的探讨,可通过github项目官方群一起交流讨论。
社区
官网:https://xiaojusurvey.didi.cn/
项目地址:https://github.com/didi/xiaoju-survey
微信:
